
招聘信息可视化系统
一、介绍
此系统是一个实时分析招聘信息系统,应用Python爬虫、Flask框架、Echarts等技术实现。
系统用户分为三类,管理员,普通用户和特殊用户(特殊用户指残疾人用户),普通用户和特殊用户的招聘数据来源不同,分别展示各自的数据
二、系统功能
登录注册
所有用户可登录与注册操作
管理员功能界面
1、个人信息
浏览或修改个人信息
![图片[1]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113024680-1024x526.png)
2、修改密码
修改登录密码
![图片[2]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113041418-1024x526.png)
3、51Jib数据概览
浏览正常用户招聘数据
![图片[3]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113135977-1024x526.png)
4、残疾人招聘数据概览
浏览特殊用户招聘数据
![图片[4]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113150586-1024x526.png)
5、51job数据获取
动态获取51job数据
![图片[5]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113202879-1024x526.png)
6、数据爬取日志
查看数据爬取日志
![图片[6]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113235956-1024x526.png)
7、用户管理
管理系统用户
![图片[7]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113257598-1024x526.png)
普通用户功能界面
1、个人信息
浏览或修改个人信息
![图片[8]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113430426-1024x526.png)
2、修改密码
修改登录密码
![图片[9]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113447631-1024x526.png)
3、职位数据
将爬取到的数据进行展示
![图片[10]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113504807-1024x526.png)
4、数据获取
动态获取51job数据
![图片[11]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113532948-1024x526.png)
5、数据爬取日志
查看数据爬取日志
![图片[12]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113555697-1024x526.png)
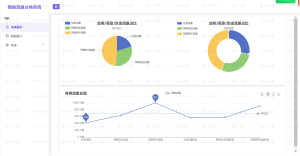
6、城市招聘分布
将数据通过工作城市进行分组,计算每个城市有多少条招聘信息,通过echarts柱状图进行展示
![图片[13]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113608552-1024x526.png)
7、福利词云
分析公司福利, 用词云图进行展示
![图片[14]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113632781-1024x526.png)
8、薪资统计
通过行业、学历要求和工作地点分析薪资占比
![图片[15]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113642237-1024x526.png)
9、招聘要求
经验和学历两个维度分析各个行业的招聘要求占比
![图片[16]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113659286-1024x526.png)
10、公司信息分析
对公司属性、公司性质、公司规模进行分析
![图片[17]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526113719589-1024x526.png)
11、推荐职位
根据个人信息系统推荐合适的职位
12、薪资预测
通过工资中位数对薪资进行预测
![图片[18]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526114013445-1024x526.png)
特殊用户功能
1、个人信息
浏览或修改个人信息
![图片[19]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526114108394-1024x526.png)
2、修改密码
修改登录密码
![图片[20]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526114121720-1024x526.png)
3、职位数据
将爬取到的数据进行展示
![图片[21]-0089A招聘信息可视化系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2024/05/20240526114140457-1024x526.png)
4、城市招聘分布
将数据通过工作城市进行分组,计算每个城市有多少条招聘信息,通过echarts柱状图进行展示
5、福利词云
分析公司福利, 用词云图进行展示
6、薪资统计
通过行业、学历要求和工作地点分析薪资占比
7、招聘要求
经验和学历两个维度分析各个行业的招聘要求占比
8、公司信息分析
对公司属性、公司性质、公司规模进行分析
9、推荐职位
根据个人信息系统推荐合适的职位
10、薪资预测
通过工资中位数对薪资进行预测
三、软件架构
后端
- python
- flask
前端
- vue
- iview
- echarts
python库
# 升级pip库,如果已升级可忽略
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
python -m pip install --upgrade pip
# flask库
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Flask
# pymysql
pip install pymysql
#requests
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
#xlwt
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlwt
#jieba
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba
#wordcloud
pip --default-timeout=100 install wordcloud
#lxml
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml
#BeautifulSoup4
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple BeautifulSoup4
#fake_useragent
pip install fake_useragent四、安装教程
- 安装上述所有python库
- 启动flask
# 启动flask命令
python app.py- 安装node.js
- 安装vue库
- 启动vue
# 安装vue库
npm i
# 启动vue
npm run serve- 访问
http://localhost:8099/五、工程目录结构
|zhaopin
|-- zp_server 后端目录
|-- data 爬虫目录
|-- data_boss.py 爬虫-BOSS直聘(未用,可删)
|-- data_canji.py 爬虫-残疾人招聘信息
|-- data_job.py 爬虫-前程无忧(未用,可删)
|-- data_job.py 爬虫-前程无忧,改版前(未用,可删)
|-- data_log.py 爬虫日志保存通用类
|-- data_qcwy.py 爬虫-前程无忧,改版后(未用,可删)
|-- data_zhilian.py 爬虫-智联招聘
|-- mysqlHelper.py mysql工具类
|-- app.py flask启动类
|-- bus_cloud.py 接口-生成词云图
|-- bus_index.py 接口-系统管理(通用、管理员功能)
|-- bus_putong.py 接口-普通用户
|-- bus_teshu.py 接口-特殊用户
|-- zhongweishu.py 中位数计算工具类
|-- jd_web
|-- node_modules node包
|-- public 结构文件
|-- src
|--api 接口,对应后端的接口
|--assets 静态文件
|--components 系统组件
|--router 路由
|--store 路由
|--utils 工具类
|--views 页面
|-- tests 单元测试
|-- vue.config.js vue配置类六、表结构
|p_job
|-- tbl_city 城市字典表
|-- tbl_data_log 数据爬取日志表
|-- tbl_job 51job职位信息表
|-- tbl_job_canji 残疾人招聘信息表
|-- tbl_user 用户表
|-- tbl_user_job 用户职位收藏表七、特别说明
此系统爬虫脚本仅可用户学习交流,切勿爬取大量数据,对网站服务器施压!!!
词云说明
bus_cloud:部署时需配置词云图片位置
爬虫说明
- data_canji.py
该爬虫用户爬取 中国残联就业创业网络服务平台 信息,爬取前指定爬取页数,系统自动循环爬取
# 目标地址
https://www.cdpee.org.cn/job/
# 防反爬设置
设置cookies,headers等信息,伪装成浏览器
每页爬取完延时3秒
# 参数设置
pageSize:需要爬取的总页数- data_zhilian.py
该爬虫用户爬取 智联招聘 信息,爬取前指定爬取页数,系统自动循环爬取
# 目标地址
https://landing.zhaopin.com/
# 特别注意!!!
爬虫失败后需要登录智联招聘,拿到最新的cookie在源码中进行替换,替换完毕后重启系统
# 防反爬设置
设置cookies,headers等信息,伪装成浏览器
每页爬取完延时3秒
# 参数设置
city_id:城市编号,默认000000(全国),可自行配置,(tbl_city 表中有相关数据)
job_type:职位名称 (尽量精准,爬取到的数据会更贴切),每次爬取前会根据关键词删除历史数据,防止数据重复
pages:页数(自己指定,注意不要超过总页数)!!!为了防止爬取过多ip被封,尽量一次一两页这样爬取爬虫cookie教学视频
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END


暂无评论内容