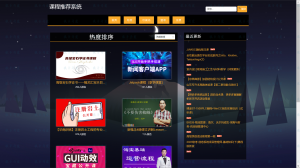

系统技术框架简介- 前端: bootstrap3 + jquery.js
- 前端: bootstrap3 + jquery.js
- 后端: django 2.2.1 + djangorestframework(负责api部分)
- 数据库: mysql5.7
- 算法: 基于用户的协同过滤/基于物品的协同过滤
数据集简介
基于requests的python爬虫去抓取腾讯课程的课程信息,包含图片信息,总共1000部。
数据属性:
![图片[1]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/01/20230123002940296-1024x654.png)
评分: 附带随机生成数据的脚本,可以随机生成指定数目的用户和用户的评分
movielens数据集
movielens 100k数据集+图片
数据维度: movieId,title,genres,picture
课程数量: 1000
评分数量: 93202+
movielens数据集+图片+用户数据和评分数据+csv存储
功能简介
课程展示,课程搜索,标签分类
![图片[2]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/05/20230510001537282-1024x574.png)
标签分类
![图片[3]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/05/20230510001558657-1024x574.png)
用户的登录,注册,修改信息
用户注册界面
![图片[4]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/01/20230123003536957-1024x574.png)
用户登录界面
![图片[5]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/01/20230123003557321-1024x574.png)
用户个人信息
![图片[6]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/01/20230123003633848-1024x574.png)
用户注册代码
#注册
class RegisterForm(forms.Form):
username = forms.CharField(
label="昵称(不可重复)",
max_length=50,
widget=forms.TextInput(attrs={"class": "form-control", 'placeholder': '昵称(不可重复)'}),
)
email = forms.EmailField(
label="邮箱", widget=forms.EmailInput(attrs={"class": "form-control", 'placeholder': '邮箱'})
)
password1 = forms.CharField(
label="密码",
max_length=128,
widget=forms.PasswordInput(attrs={"class": "form-control", 'placeholder': '密码'}),
)
password2 = forms.CharField(
label="确认密码",
widget=forms.PasswordInput(attrs={"class": "form-control", 'placeholder': '确认密码'}),
)
#以下为信息验证
def clean_username(self):
username = self.cleaned_data.get("username")
if len(username) < 6:
raise forms.ValidationError(
"Your username must be at least 6 characters long."
)
elif len(username) > 50:
raise forms.ValidationError("Your username is too long.")
else:
filter_result = User.objects.filter(username=username)
if len(filter_result) > 0:
raise forms.ValidationError("Your username already exists.")
return username
def clean_name(self):
name = self.cleaned_data.get("name")
filter_result = User.objects.filter(name=name)
if len(filter_result) > 0:
raise forms.ValidationError("Your name already exists.")
return name
def clean_password1(self):
password1 = self.cleaned_data.get("password1")
if len(password1) < 6:
raise forms.ValidationError("Your password is too short.")
elif len(password1) > 20:
raise forms.ValidationError("Your password is too long.")
return password1
def clean_password2(self):
password1 = self.cleaned_data.get("password1")
password2 = self.cleaned_data.get("password2")
if password1 and password2 and password1 != password2:
raise forms.ValidationError("Password mismatch. Please enter again.")
return password2
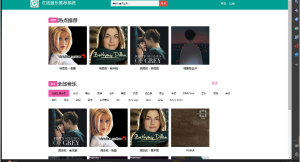
基于user和Item的协同过滤推荐
用户推荐和物品推荐界面
![图片[7]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/05/20230510001632809-1024x574.png)
用户推荐代码
# 基于用户的推荐
def recommend_by_user_id(user_id):
user_prefer = UserTagPrefer.objects.filter(user_id=user_id).order_by('-score').values_list('tag_id', flat=True)
current_user = User.objects.get(id=user_id)
# 如果当前用户没有打分 则看是否选择过标签,选过的话,就从标签中找
# 没有的话,就按照浏览度推荐15个
if current_user.rate_set.count() == 0:
if len(user_prefer) != 0:
movie_list = Movie.objects.filter(tags__in=user_prefer)[:15]
else:
movie_list = Movie.objects.order_by("-num")[:15]
return movie_list
# 选取评分最多的10个用户
users_rate = Rate.objects.values('user').annotate(mark_num=Count('user')).order_by('-mark_num')
user_ids = [user_rate['user'] for user_rate in users_rate]
user_ids.append(user_id)
users = User.objects.filter(id__in=user_ids)#users 为评分最多的10个用户
all_user = {}
for user in users:
rates = user.rate_set.all()#查出10名用户的数据
rate = {}
# 用户有给课程打分 在rate和all_user中进行设置
if rates:
for i in rates:
rate.setdefault(str(i.movie.id), i.mark)#填充课程数据
all_user.setdefault(user.username, rate)
else:
# 用户没有为课程打过分,设为0
all_user.setdefault(user.username, {})
user_cf = UserCf(all_user=all_user)
recommend_list = [each[0] for each in user_cf.recommend(current_user.username, 15)]
movie_list = list(Movie.objects.filter(id__in=recommend_list).order_by("-num")[:15])
other_length = 15 - len(movie_list)
if other_length > 0:
fix_list = Movie.objects.filter(~Q(rate__user_id=user_id)).order_by('-collect')
for fix in fix_list:
if fix not in movie_list:
movie_list.append(fix)
if len(movie_list) >= 15:
break
return movie_list
# 计算相似度
def similarity(movie1_id, movie2_id):
movie1_set = Rate.objects.filter(movie_id=movie1_id)
# movie1的打分用户数
movie1_sum = movie1_set.count()
# movie_2的打分用户数
movie2_sum = Rate.objects.filter(movie_id=movie2_id).count()
# 两者的交集
common = Rate.objects.filter(user_id__in=Subquery(movie1_set.values('user_id')), movie=movie2_id).values('user_id').count()
# 没有人给当前课程打分
if movie1_sum == 0 or movie2_sum == 0:
return 0
similar_value = common / sqrt(movie1_sum * movie2_sum)#余弦计算相似度
return similar_value
物品推荐部分代码
#基于物品
def recommend_by_item_id(user_id, k=15):
# 前三的tag,用户评分前三的课程
user_prefer = UserTagPrefer.objects.filter(user_id=user_id).order_by('-score').values_list('tag_id', flat=True)
user_prefer = list(user_prefer)[:3]
current_user = User.objects.get(id=user_id)
# 如果当前用户没有打分 则看是否选择过标签,选过的话,就从标签中找
# 没有的话,就按照浏览度推荐15个
if current_user.rate_set.count() == 0:
if len(user_prefer) != 0:
movie_list = Movie.objects.filter(tags__in=user_prefer)[:15]
else:
movie_list = Movie.objects.order_by("-num")[:15]
print('from here')
return movie_list
# most_tags = Tags.objects.annotate(tags_sum=Count('name')).order_by('-tags_sum').filter(movie__rate__user_id=user_id).order_by('-tags_sum')
# 选用户最喜欢的标签中的课程,用户没看过的30部,对这30部课程,计算距离最近
un_watched = Movie.objects.filter(~Q(rate__user_id=user_id), tags__in=user_prefer).order_by('?')[:30] # 看过的课程
watched = Rate.objects.filter(user_id=user_id).values_list('movie_id', 'mark')
distances = []
names = []
# 在未看过的课程中找到
for un_watched_movie in un_watched:
for watched_movie in watched:
if un_watched_movie not in names:
names.append(un_watched_movie)
distances.append((similarity(un_watched_movie.id, watched_movie[0]) * watched_movie[1], un_watched_movie))#加入相似的课程
distances.sort(key=lambda x: x[0], reverse=True)
print('this is distances', distances[:15])
recommend_list = []
for mark, movie in distances:
if len(recommend_list) >= k:
break
if movie not in recommend_list:
recommend_list.append(movie)
# print('this is recommend list', recommend_list)
# 如果得不到有效数量的推荐 按照未看过的课程中的热度进行填充
print('recommend list', recommend_list)
return recommend_list
if __name__ == '__main__':
similarity(2003, 2008)
recommend_by_item_id(1)后台管理系统界面,可以进行课程信息的增删改查
![图片[8]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/05/20230510001737444-1024x574.png)
![图片[9]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/05/20230510001901776-1024x574.png)
数据库简介
数据库模型代码
#数据库表
class User(models.Model):
username = models.CharField(max_length=255, unique=True, verbose_name="账号")#unique唯一(不重复)
password = models.CharField(max_length=255, verbose_name="密码")
email = models.EmailField(verbose_name="邮箱")
created_time = models.DateTimeField(auto_now_add=True)
class Meta:
verbose_name_plural = "用户"
verbose_name = "用户"
def __str__(self):
return self.username
class Tags(models.Model):
name = models.CharField(max_length=255, verbose_name="标签", unique=True)
class Meta:
verbose_name = "标签"
verbose_name_plural = "标签"
def __str__(self):
return self.name
class UserTagPrefer(models.Model):
user = models.ForeignKey(
User, on_delete=models.CASCADE, blank=True, verbose_name="用户id",
)
tag = models.ForeignKey(Tags, on_delete=models.CASCADE, verbose_name='标签名')
score = models.FloatField(default=0)
class Meta:
verbose_name = "用户偏好"
verbose_name_plural = "偏好"
def __str__(self):
return self.user.username + str(self.score)
class Movie(models.Model):
tags = models.ManyToManyField(Tags, verbose_name='标签', blank=True)#多对多关系
collect = models.ManyToManyField(User, verbose_name="收藏者", blank=True)
name = models.CharField(verbose_name="课程名称", max_length=255, unique=True)
director = models.CharField(verbose_name="导演名称", max_length=255)
country = models.CharField(verbose_name="国家", max_length=255)
years = models.DateField(verbose_name='上映日期')
leader = models.CharField(verbose_name="主演", max_length=1024)
d_rate_nums = models.IntegerField(verbose_name="腾讯评价数")
d_rate = models.CharField(verbose_name="腾讯评分", max_length=255)
intro = models.TextField(verbose_name="描述")
num = models.IntegerField(verbose_name="浏览量", default=0)
origin_image_link = models.URLField(verbose_name='腾讯图片地址', max_length=255, null=True)
image_link = models.FileField(verbose_name="封面图片", max_length=255, upload_to='movie_cover')
imdb_link = models.URLField(null=True)
@property
def movie_rate(self):
movie_rate = Rate.objects.filter(movie_id=self.id).aggregate(Avg('mark'))['mark__avg']
return movie_rate or '无'
class Meta:
verbose_name = "课程"
verbose_name_plural = "课程"
def __str__(self):
return self.name
def to_dict(self, fields=None, exclude=None):
opts = self._meta
data = {}
for f in chain(opts.concrete_fields, opts.private_fields, opts.many_to_many):
if exclude and f.name in exclude:
continue
if fields and f.name not in fields:
continue
value = f.value_from_object(self)
if isinstance(value, date):
value = value.strftime('%Y-%m-%d')
elif isinstance(f, FileField):
value = value.url if value else None
data[f.name] = value
return data
算法简介
系统采用基于用户/物品的协同过滤算法
基于用户的协同过滤
算法: 根据用户对课程的打分来进行推荐。根据皮尔森相关系数 从所有打分的用户中找出和当前用户距离最近的n用户,然后从n个用户看过的课程中找15个当前用户未看过的课程。
皮尔逊(Pearson)距离公式:
![图片[10]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/01/20230123112002129.png)
基于物品的协同过滤
- 计算用户的共现矩阵
遍历所有用户的评分值,存储课程之间被相同用户看过的值
![图片[11]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://pic4.zhimg.com/80/v2-3bab5508882603158180cdecce63c64b_1440w.webp)
2. 计算物品相似度,这里计算相似度并没有引进物品的属性,而是简单地通过分析用户的历史行为记录进行计算,N(i)代表喜欢物品i的用户数量,w(j)代表喜欢物品j的用户数量,通过余弦相似度来计算两个物品间的距离。
![图片[12]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/01/20230123112135297.png)
3. 通过以下公式来计算用户u对物品j的兴趣 N(u)用户u看过的课程。w(j,i)代表物品j和物品i的相似度 s(j,k)代表和物品j最相似的k个课程集合。
选取k个用户u看过的和课程j最相似的课程, rui代表用户u对物品i的兴趣,这里用用户u对物品i的打分值来代替
![图片[13]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/01/20230123112738817.png)
将与物品j距离最近的k件物品U同时是用户u看过的作为i,将用户对i的得分和i与j的权重值进行想成并且累加,得到用户u对物品j的喜爱值。选取n件推荐给用户。
相似度:共现值/N的点赞值*M的点赞值 开根号
推荐值: 相似度*评分
根据用户点赞过得商品来寻找相似度推荐。
计算每个点赞过的物品和所有未点赞物品之间的得分。得分=相似度*打分值
得分越高表示越相似。 然后返回结果
冷启动问题解决
在用户首次注册的时候会为用户提供感兴趣的标签选择界面。然后在用户未进行打分的情况下,会为用户推荐喜欢标签的课程。
![图片[14]-基于Django和协同过滤的课程推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/05/20230510001835425-1024x574.png)
对算法改进——结合标签的协同过滤推荐
在冷启动页面用户选择标签后将用户对这些标签标签的喜爱值设为5。 在用户为课程打分后,会根据此课程的标签来更新用户对标签喜爱值得分。在根据协同过滤得到为用户推荐的课程后,如果推荐的课程数量不足15部,则从用户喜爱的标签中选取一部分课程来填充。
更新标签喜爱值的策略将用户对课程的打分值减三然后加到喜爱值表中。
本项目含一万字参考论文,有需要购买下载。


暂无评论内容