
1.课题背景
由于网络信息科技的不断进步和数据量的快速增长每天会产生巨大的信息量,使得互联网上的数据信息越来越庞大、系统变得越来越臃肿,这些庞大的海量信息给用户寻找自己感兴趣的内容带来了极大的困难,往往会导致用户迷失在信息迷宫中,从而无法找到自己真正感兴趣的内容。因此,高效快速的进行新闻推荐变得极其重要。
2.实现效果
整体软件结构
![图片[1]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304022007658-1024x324.png)
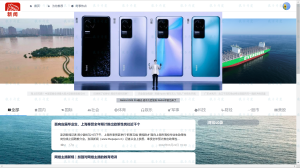
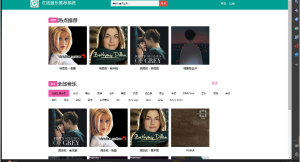
2.1用户端
![图片[2]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304022209119-1024x574.png)
![图片[3]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304022210842-1024x574.png)
![图片[4]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304022206506-1024x574.png)
![图片[5]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304022203337-1024x574.png)
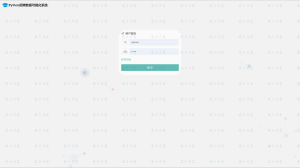
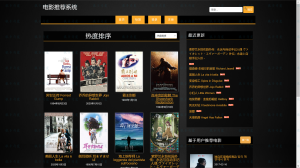
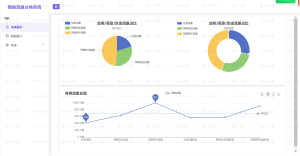
2.2 管理员端
![图片[6]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304022338731-1024x574.png)
![图片[7]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304022339186-1024x574.png)
![图片[8]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304022339721-1024x574.png)
![图片[9]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304022339178-1024x574.png)
![图片[10]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304022340532-1024x574.png)
![图片[11]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304022339486-1024x574.png)
![图片[12]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304022339537-1024x574.png)
3.Django
简介
Django是一个基于Web的应用框架,由python编写。Web开发的基础是B/S架构,它通过前后端配合,将后台服务器的数据在浏览器上展现给前台用户的应用。Django本身是基于MVC模型,即Model(模型)+View(视图)+ Controller(控制器)设计模式,View模块和Template模块组成了它的视图部分,这种结构使动态的逻辑是剥离于静态页面处理的。 Django框架的Model层本质上是一套ORM系统,封装了大量的数据库操作API,开发人员不需要知道底层的数据库实现就可以对数据库进行增删改查等操作。Django强大的QuerySet设计能够实现非常复杂的数据库查询操作,且性能接近原生SQL语句。Django支持包括PostgreSQL、My Sql、SQLite、Oracle在内的多种数据库。Django的路由层设计非常简洁,使得将控制层、模型层和页面模板独立开进行开发成为可能。基于Django的Web系统工程结构示意图如图所示。
4.爬虫
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。爬虫对某一站点访问,如果可以访问就下载其中的网页内容,并且通过爬虫解析模块解析得到的网页链接,把这些链接作为之后的抓取目标,并且在整个过程中完全不依赖用户,自动运行。若不能访问则根据爬虫预先设定的策略进行下一个 URL的访问。在整个过程中爬虫会自动进行异步处理数据请求,返回网页的抓取数据。在整个的爬虫运行之前,用户都可以自定义的添加代理,伪装请求头以便更好地获取网页数据。爬虫流程图如下:
![图片[13]-python 爬虫与协同过滤的新闻推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304115712285.png)
def getnewsdetail(url):
# 获取页面上的详情内容并将详细的内容汇集在news集合中
result = requests.get(url)
result.encoding = 'utf-8'
soup = BeautifulSoup(result.content, features="html.parser")
title = getnewstitle(soup)
if title == None:
return None
date = getnewsdate(soup)
mainpage, orimainpage = getmainpage(soup)
if mainpage == None:
return None
pic_url = getnewspic_url(soup)
videourl = getvideourl(url)
news = {'mainpage': mainpage,
'pic_url': pic_url,
'title': title,
'date': date,
'videourl': videourl,
'origin': orimainpage,
}
return news
def getmainpage(soup):
'''
@Description:获取正文部分的p标签内容,网易对正文部分的内容通过文本前部的空白进行标识\u3000
@:param None
'''
if soup.find('div', id='article') != None:
soup = soup.find('div', id='article')
p = soup.find_all('p')
for numbers in range(len(p)):
p[numbers] = p[numbers].get_text().replace("\u3000", "").replace("\xa0", "").replace("新浪", "新闻")
text_all = ""
for each in p:
text_all += each
logger.info("mainpage:{}".format(text_all))
return text_all, p
elif soup.find('div', id='artibody') != None:
soup = soup.find('div', id='artibody')
p = soup.find_all('p')
for numbers in range(len(p)):
p[numbers] = p[numbers].get_text().replace("\u3000", "").replace("\xa0", "").replace("新浪", "新闻")
text_all = ""
for each in p:
text_all += each
logger.info("mainpage:{}" + text_all)
return text_all, p
else:
return None, None
def getnewspic_url(soup):
'''
@Description:获取正文部分的pic内容,网易对正文部分的图片内容通过div中class属性为“img_wrapper”
@:param None
'''
pic = soup.find_all('div', class_='img_wrapper')
pic_url = re.findall('src="(.*?)"', str(pic))
for numbers in range(len(pic_url)):
pic_url[numbers] = pic_url[numbers].replace("//", 'https://')
logging.info("pic_url:{}".format(pic_url))
return pic_url
5.VUE
Vue是一套用于构建用户界面的渐进式框架。其核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。
6.推荐算法
基于协同过滤的推荐算法(Collaborative Filtering Recommendations)
协同过滤(Collaborative Filtering)推荐算法是最经典、最常用的推荐算法。
所谓协同过滤, 基本思想是根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品(基于对用户历史行为数据的挖掘发现用户的喜好偏向, 并预测用户可能喜好的产品进行推荐),一般是仅仅基于用户的行为数据(评价、购买、下载等), 而不依赖于项的任何附加信息(物品自身特征)或者用户的任何附加信息(年龄,性别等)。目前应用比较广泛的协同过滤算法是基于邻域的方法, 而这种方法主要有下面两种算法:
基于用户的协同过滤算法(UserCF): 给用户推荐和他兴趣相似的其他用户喜欢的产品
基于物品的协同过滤算法(ItemCF): 给用户推荐和他之前喜欢的物品相似的物品
7.APScheduler框架
Advanced Python Scheduler (APScheduler) 是一个 Python 库,可让您安排 Python 代码稍后执行,可以只执行一次,也可以定期执行。您可以随意添加新工作或删除旧工作。如果您将任务存储在数据库中,它们也将在调度器重新启动后幸存下来并保持其状态。当调度器重新启动时,它将运行它在离线时应该运行的所有任务。
除此之外,APScheduler 可以用作跨平台、特定于应用程序的平台特定调度器的替代品,例如 cron 守护程序或 Windows 任务调度器。但是请注意,APScheduler 本身不是守护程序或服务,也不附带任何命令行工具。它主要用于在现有应用程序中运行。也就是说,APScheduler 确实为您提供了一些构建块来构建调度器服务或运行专用调度器进程。
from apscheduler.schedulers.blocking import BlockingScheduler
from Recommend.NewsRecommendByCity import beginrecommendbycity
from Recommend.NewsRecommendByHotValue import beginrecommendbyhotvalue
from Recommend.NewsRecommendByTags import beginNewsRecommendByTags
from Recommend.NewsKeyWordsSelect import beginSelectKeyWord
from Recommend.NewsHotValueCal import beginCalHotValue
from Recommend.NewsCorrelationCalculation import beginCorrelation
from Recommend.HotWordLibrary import beginHotWordLibrary
sched = BlockingScheduler()
sched2 = BlockingScheduler()
def beginRecommendSystem(time):
'''
@Description:推荐系统启动管理器(基于城市推荐、基于热度推荐、基于新闻标签推荐)
@:param time --> 时间间隔
'''
sched.add_job(func=beginrecommendbycity, trigger='interval', max_instances=1, seconds=int(time),
id='NewsRecommendByCity',
kwargs={})
sched.add_job(beginrecommendbyhotvalue, 'interval', max_instances=1, seconds=int(time),
id='NewsRecommendByHotValue',
kwargs={})
sched.add_job(beginNewsRecommendByTags, 'interval', max_instances=1, seconds=int(time), id='NewsRecommendByTags',
kwargs={})
sched.start()
def stopRecommendSystem():
'''
@Description:推荐系统关闭管理器
@:param None
'''
sched.remove_job('NewsRecommendByCity')
sched.remove_job('NewsRecommendByHotValue')
sched.remove_job('NewsRecommendByTags')
def beginAnalysisSystem(time):
'''
@Description:数据分析系统启动管理器(关键词分析、热词分析、新闻相似度分析、热词统计)
@:param time --> 时间间隔
'''
sched2.add_job(beginSelectKeyWord, trigger='interval', max_instances=1, seconds=int(time),
id='beginSelectKeyWord',
kwargs={"_type": 2})
sched2.add_job(beginCalHotValue, 'interval', max_instances=1, seconds=int(time),
id='beginCalHotValue',
kwargs={})
sched2.add_job(beginCorrelation, 'interval', max_instances=1, seconds=int(time), id='beginCorrelation',
kwargs={})
sched2.add_job(beginHotWordLibrary, 'interval', max_instances=1, seconds=int(time), id='beginHotWordLibrary',
kwargs={})
sched2.start()
def stopAnalysisSystem():
'''
@Description:数据分析系统关闭管理器
@:param None
'''
sched2.remove_job('beginSelectKeyWord')
sched2.remove_job('beginCalHotValue')
sched2.remove_job('beginCorrelation')
sched2.remove_job('beginHotWordLibrary')
sched2.shutdown()


暂无评论内容