
程序主要采用Python 爬虫+flask框架+html+javascript实现岗位推荐分析可视化系统,实现工作岗位的实时发现,推荐检索,快速更新以及工作类型的区域分布效果,关键词占比分析等。
程序模块实现
注册登录模块
![图片[1]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012859641-1024x574.png)
登录后个人中心页
![图片[2]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012859234-1024x574.png)
![图片[3]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012900842-1024x574.png)
![图片[4]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012900927-1024x574.png)
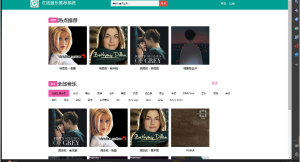
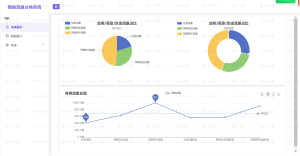
招聘数据可视化
![图片[5]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012900142-1024x574.png)
![图片[6]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012900976-1024x574.png)
![图片[7]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012900196-1024x574.png)
![图片[8]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012900730-1024x574.png)
![图片[9]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012900229-1024x574.png)
![图片[10]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012900561-1024x574.png)
![图片[11]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012900912-1024x574.png)
薪资预测模块
![图片[12]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012900492-1024x574.png)
预测模型:决策树、最近邻、逻辑回归、朴素贝叶斯、神经网络、随机森林、支持向量机
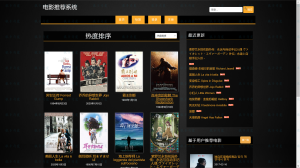
网站搜索模块
![图片[13]-Python爬虫+可视化分析技术实现招聘网站岗位数据抓取与分析推荐系统-软件开发指导](https://code-1258723414.cos.ap-shanghai.myqcloud.com/2023/03/20230304012900552-1024x574.png)
Python爬虫设计
本次毕设系统在Python爬虫模块设计中,主要采用拉勾网作为数据收集来源,利用Python Request模块实现对站点岗位数据的收集与去重,动态过滤种子URL地址,写入Mysql数据库,完成工作岗位数据的采集与分析。
爬虫核心代码
import requests
import math
import time
import pandas as pd
import pymysql
from sqlalchemy import create_engine
def get_json(url, num):
"""
从指定的url中通过requests请求携带请求头和请求体获取网页中的信息,
:return:
"""
url1 = 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest',
'Cookie':'user_trace_token=20230301112856-33ed036d-183d-4b19-8a9c-3e8a116078ba; __lg_stoken__=3849ce7ef8cf0df229a2c8ed12f1ef5dd7d2bb03b0869718ce0de8aa6ed124efea00b05d583e1e84d4d844fd093cfbf8f695c2f88e10ffa756da6e1af8200030bb8bf7b9b429; X_HTTP_TOKEN=9dbadcf976352a837331467761347db00d0dec4d55; _ga=GA1.2.344596115.1677641338; LGUID=20230301112858-1122e40d-9251-4728-bd2e-3d8e0a5b70fb; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1677641338,1677737144; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1677737144; _gid=GA1.2.224232936.1677737144; LGSID=20230302140543-4928bcce-faf0-4c7d-b07b-3ccc2e29c20f; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fpassport.lagou.com%2Flogin%2Flogin.html%3Fsignature%3D2A27BB6F4BFD2EC7D3315727800B2BFC%26service%3Dhttp%25253A%25252F%25252Fwww.lagou.com%25252Fjobs%25252F%26action%3Dlogin%26serviceId%3Dlagou%26ts%3D1677737142841; LGRID=20230302140543-7b54ad4b-1ee8-4a1c-8f5e-f3c3e031361f; gate_login_token=v1####46e70a42d09135b8f753821807b5d67fcf9a3c0b2ae20044e6803e3453174f47; LG_HAS_LOGIN=1; _putrc=9BE7CBE6BAE457BF123F89F2B170EADC; login=true; privacyPolicyPopup=false; sensorsdata2015session=%7B%7D; unick=%E8%A4%9A%E7%91%9E%E9%9B%AA; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221869b374994a20-0518497f9b91da-7a575473-1265047-1869b374995959%22%2C%22%24device_id%22%3A%221869b374994a20-0518497f9b91da-7a575473-1265047-1869b374995959%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24os%22%3A%22Windows%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%22108.0.0.0%22%7D%7D'
}
data = {
'first': 'true',
'pn': num,
'kd': 'python开发工程师'} #这里修改需要爬取的岗位名称,例如: BI工程师 python开发工程师
#得到Cookies信息
s = requests.Session()
print('建立session:', s, '\n\n')
s.get(url=url1, headers=headers, timeout=3)
cookie = s.cookies
print('获取cookie:', cookie, '\n\n')
#添加请求参数以及headers、Cookies等信息进行url请求
res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3)
res.raise_for_status()
res.encoding = 'utf-8'
page_data = res.json()
print('请求响应结果:', page_data, '\n\n')
return page_data
def get_page_num(count):
"""
计算要抓取的页数,通过在拉勾网输入关键字信息,可以发现最多显示30页信息,每页最多显示15个职位信息
:return:
"""
page_num = math.ceil(count / 15)
if page_num > 29:
return 29
else:
return page_num
# 获取每一页的职位相关的信息
page_data = get_json(url, num) # 获取响应json
jobs_list = page_data['content']['positionResult']['result'] # 获取每页的所有python相关的职位信息
page_info = get_page_info(jobs_list)
total_info += page_info
print('已经爬取到第{}页,职位总数为{}'.format(num, len(total_info)))
time.sleep(20)
#将总数据转化为data frame再输出,然后在写入到csv格式的文件中以及本地mysql数据库中
df = pd.DataFrame(data=unique(total_info),
columns=['companyFullName', 'companyShortName', 'companySize', 'financeStage',
'district', 'positionName', 'workYear', 'education',
'salary', 'positionAdvantage', 'industryField',
'firstType', 'companyLabelList', 'secondType', 'city'])
df.to_csv('pachong.csv', index=True)
print('职位信息已保存本地')
df.to_sql(name='demo', con=engine, if_exists='append', index=False)
print('职位信息已保存数据库')
if __name__ == '__main__':
main()本系统,主要包括三个步骤:收集招聘岗位数据,整理数据分析统计维度,结合echarts图表实现动态展示及推荐等。本系统采用Python语言开发,所用开发工具有pycharm 2021、visual studio code、在线uml制作工具process on、Mysql5.7、 插件包含Resharper、SQL Prompt等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END


暂无评论内容